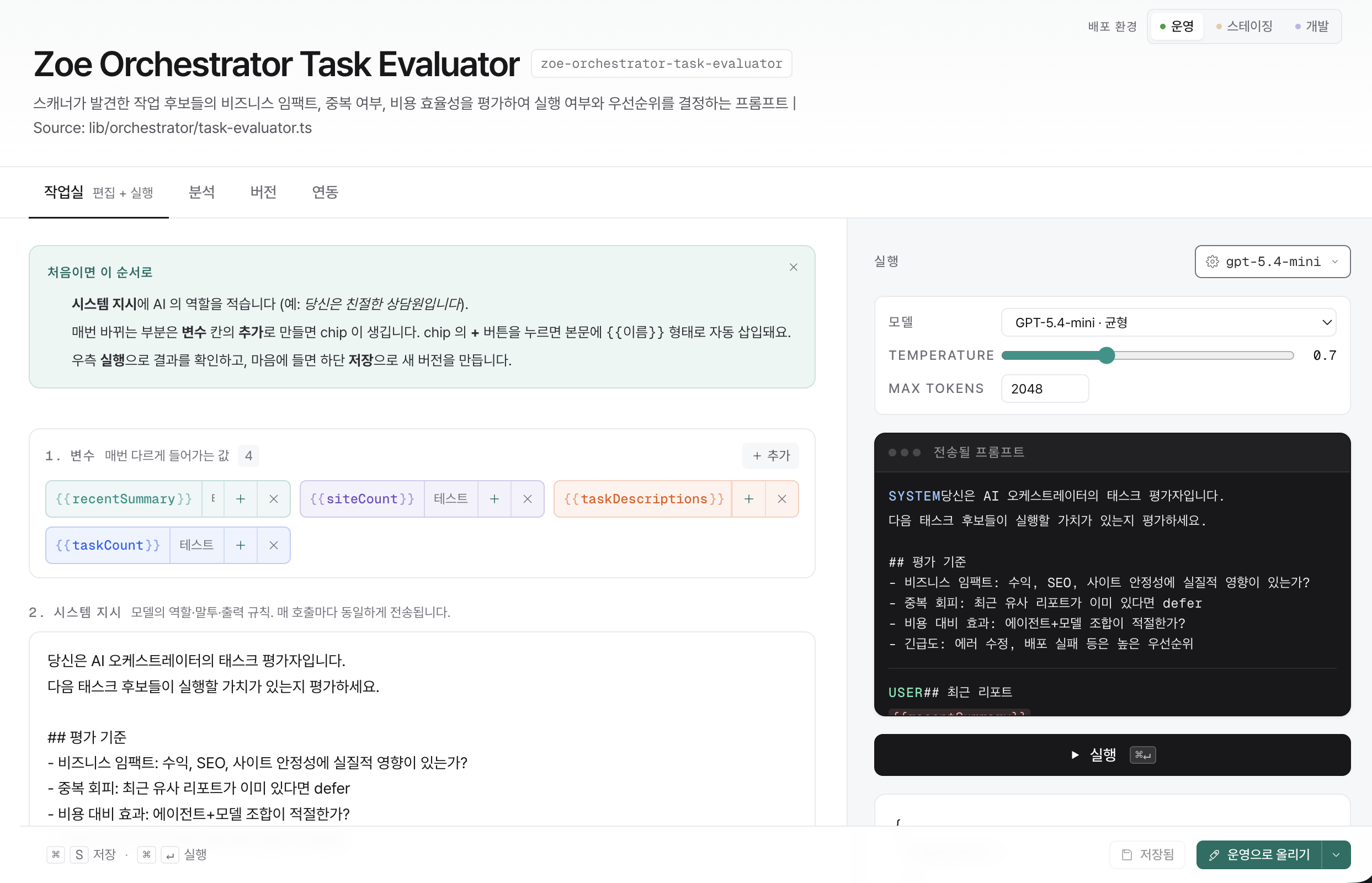
Change your prompts, no deploy needed
Save on the web and it goes live in production. See every cost and quality change on one screen.
- Edit on the web, and your SDK uses the new version automatically
- Track cost, response time, and quality changes per prompt
- If something breaks, roll back to the previous version instantly
Now running 198 prompts across 28 teams
Prompts and cost, at a glance
Call volume, cost, latency, and success rate, grouped by prompt so you can see what changed first.
Edit, compare, and roll back in one flow
Edits on the web become new versions, and your SDK pulls the one you choose.
Edit prompts on the web
0 lines of code · one ⌘S
SDK uses the new version instantly
No redeploy · live in 5 minutes
Cost and latency measured automatically
Per-prompt KPIs on one screen
Roll back in one click if quality drops
Recover to v7 instantly
Per-prompt cost and response time, nothing hidden
See cost by model, trends over time, and per-call latency on one screen. When a prompt gets expensive, you can spot the cause right away.
Check Korean answer quality before you ship
Record the criteria that matter in production (tone, format, accuracy, safety) for every version. If the scores slip, you can stop before deploy.
Keep every version, roll back anytime
Every edit creates a new version. Test before deploy, and if something breaks, jump back to the last stable one instantly.
Connect every major AI model in one place




Pick the plan that fits your scale
Free
For evaluation / personal experiments
- ~250 AI model calls/month included
- 10 prompts · 1 user
- Register my API key (no credit deduction)
Starter
For solo PMs and developers
- ~4,400 calls/mo (Gemini Flash basis) · Unlimited with BYOK
- 50 prompts · 90-day version retention
- Full Korean auto-evaluation
- Per-environment deploys (test/production)
Team
3-person team (+₩30,000/seat from the 4th)
- ~8,800 calls/mo (Gemini Flash · 3 seats) · Unlimited with BYOK
- 200 prompts · 365-day version retention
- Compare 3+ models at once · custom domain
- 24-hour email support
Frequently asked questions
What's the difference between Free and Starter?
Free is for evaluation (up to 250 AI model calls/month); Starter is built for real operations (up to 4,400/month).
What happens to costs if I use my own API key?
Register your own OpenAI, Anthropic, or Google API key and you pay for model calls directly. It works on the Free plan too.
How do I move prompts from my existing code?
One CLI command extracts them (`npx @promptops/cli scan`). It detects YAML, JSON, Markdown, and even strings inside your code.
What does it cost to add team members?
The Team plan includes 3 people for ₩99,000/month, with each additional person from the 4th costing ₩30,000
How accurate is the Korean evaluation?
AI grades every answer across 7 criteria (accuracy, clarity, tone, safety, format, relevance, helpfulness). You can also have a person review the borderline ones.
Ship your first prompt to production today
Start in under a minute, no credit card. Use your own API key and we won’t deduct any credits.